
推荐阅读若石写的这篇博客:模型不是笨,是 Harness 没配好
AI 智能体跑十步就崩,很多人第一反应是模型太蠢,但这篇文章却给出另一个视角:不是马不行,是缰绳没拴好。
文章提出的 Harness Engineering,你可以理解成给 AI 模型戴上安全带、装上安全气囊的工程实践。
IT技术
(
twitter.com
)
推荐阅读若石写的这篇博客:模型不是笨,是 Harness 没配好
AI 智能体跑十步就崩,很多人第一反应是模型太蠢,但这篇文章却给出另一个视角:不是马不行,是缰绳没拴好。
文章提出的 Harness Engineering,你可以理解成给 AI 模型戴上安全带、装上安全气囊的工程实践。
过去两年,我们经历了两个阶段:Prompt Engineering(怎么问)、Context Engineering(喂什么料),但它们对付不了模型多步自主执行时的各种意外。
文章中有一个生动的例子:让一个智能体写市场分析报告,前三步相当顺利,但到第七步突然开始胡编乱造,因为搜索返回的内容超出上下文窗口被默默截掉了;第十步输出一段残破的 JSON,整条链路就此夭折,只能重头再来。
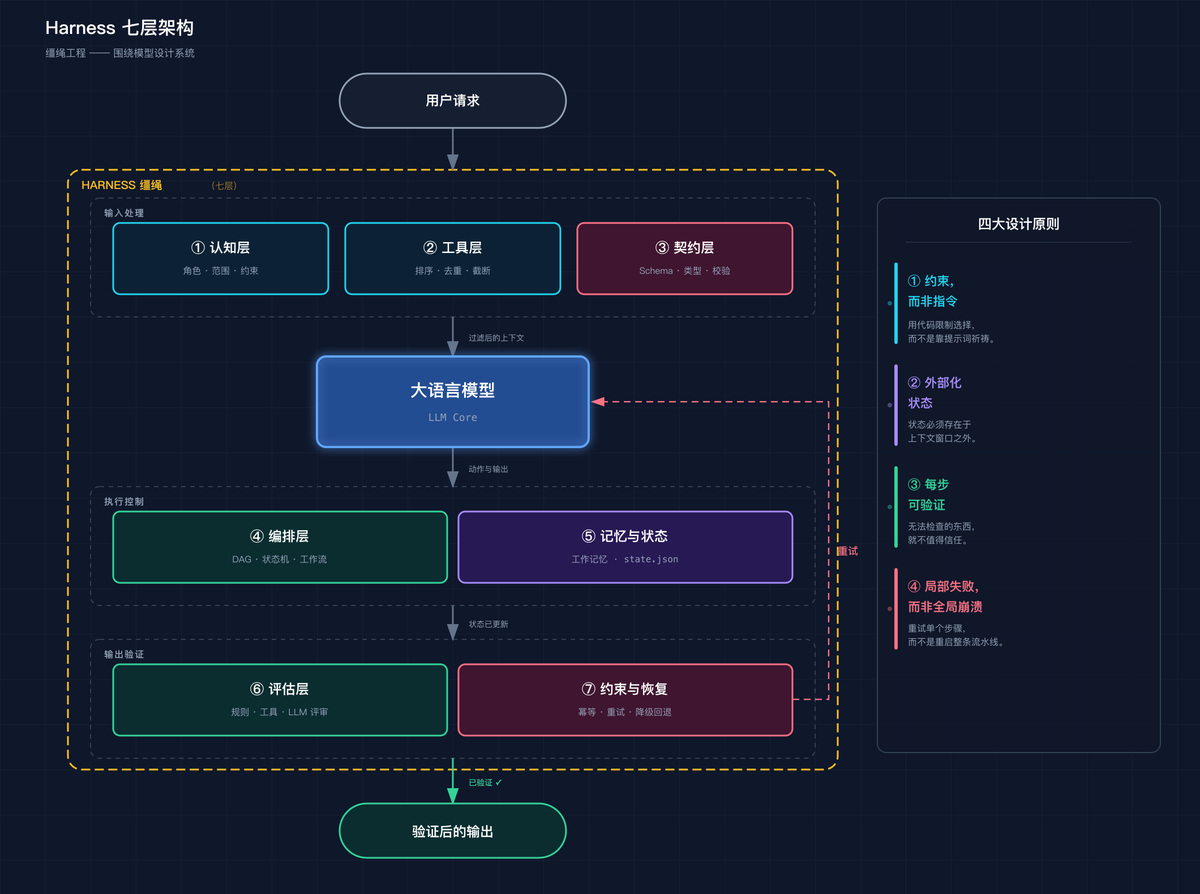
要解决这种问题,Harness Engineering 给出四个简单又实用的原则:
1. 能用代码约束的事儿,别指望模型自觉。
比如 JSON 格式,别在提示词里苦口婆心求模型输出合法内容,直接上 Schema 验证器,非法输出直接回炉。
2. 关键状态必须外置,不让模型在脑子里憋着。
就像你写代码不会只存在内存里一样,模型跑到哪一步、哪些任务完成了、哪些没做,都记到一个外部的 state.json 文件里,这样即使中途崩了,重新启动后还能接着来。
3. 模型输出不能自卖自夸,必须找第三方验收。
永远不要让模型给自己的作业评分,因为它总觉得自己很棒。需要一个独立的 Evaluator 模型,它不看原始思考过程,只对结果验收。最好还真能执行一下(跑跑编译器、打开页面看UI),而不是靠想象力评价。
4. 失败要限制在局部,不能一人出错全家连坐。
工具调用失败了,就让这一步重试,别搞得整个流程跟着陪葬。
文章后半段还提到了几个反直觉的坑:
首先是「上下文焦虑症」。
上下文一旦占了 70% 以上,模型就变得焦躁,开始跳步骤、草草收尾,好像急着下班一样。解决办法也很直观:别死守污染的上下文,干脆存盘、清空、重启一个干净实例继续干。
其次是「自评骗局」。
模型把稀烂的代码夸成“结构清晰、可读性佳”,根本不可信。真实验收标准必须独立而且有执行过程,不然你迟早翻车。
最后是「记忆整理周期」。
长期运行的智能体日志像凌乱的备忘录,新旧信息打架、浪费 token。这时候要做定期整理,把杂乱的日志压缩成清晰的状态文件。有团队靠这个技巧,把 32K token 的日志压到 7K,还一点不掉关键信息。
当然,让你一开始就搭出这种七层塔楼有点难度。
文章中提到了个一天内能落地的最小版本:
- 一个 state.json 存任务状态;
- 工具调用加 try/catch,失败就指数退避重试;
- 模型输出全都 Schema 校验;
- 工具返回的数据统一截断,绝不爆 token。
如果能做到这些,就能大幅提升智能体的任务成功率。推荐阅读原文。
点击图片查看原图

