
【訓練一個「很台」的AI有多難?一起著作權刑事告訴,揭開第一關「訓練語料」的授權困境】
时政
(
pse.is
)
【訓練一個「很台」的AI有多難?一起著作權刑事告訴,揭開第一關「訓練語料」的授權困境】 https://t.co/HRFLlACIaz
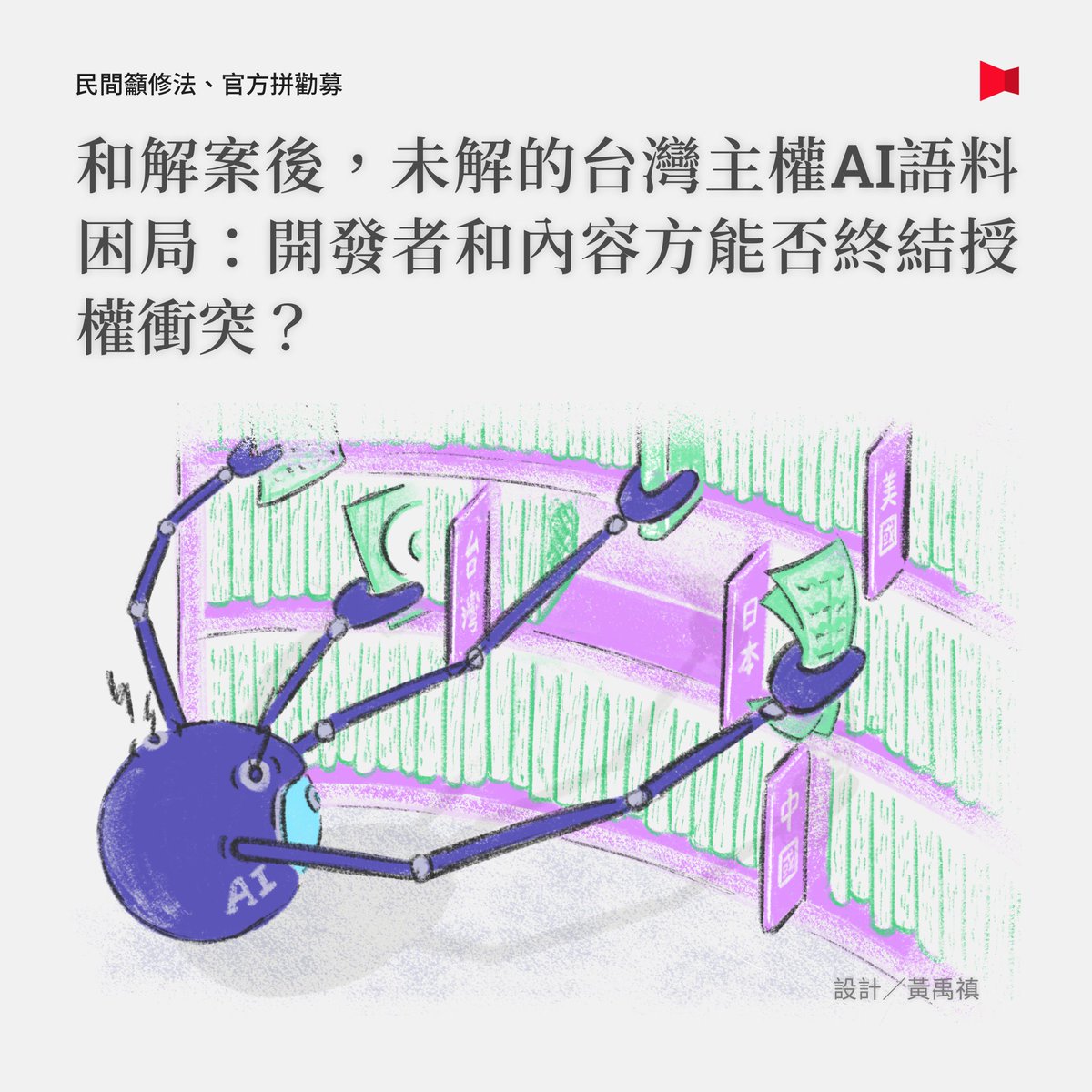
2025年7月,《中央社》對繁體中文語料集「fineweb2-zhtw」開源志工、台大博士生鍾浩霖提起刑事訴訟,原因是未取得授權,儘管最後和解落幕,但其中攸關內容產業與AI發展的著作權法規與互動機制,卻還沒有定案⋯⋯
鍾浩霖本意在於做出開源平台少有的繁體中文語料集,讓使用繁中的台灣AI開發者可以用這份資料集訓練模型,不論從文化平權、特殊專業領域應用與保護機敏資料的角度,用台灣在地語料(包括繁體中文、台語等)發展自有生成式AI模型確實有其必要,且已經參與包括國科會TAIDE計畫等多起國內AI合作的《中央社》也並非不支持這樣的目標,之所以仍選擇提告,除了沒有事先申請,關鍵在於使用者可以無償取得中央社歷史新聞,踩到內容產業在意著作權的敏感神經。
然而,翻開國內現行《著作權法》,並沒有定義「資料探勘」、「使用內容訓練AI模型」等行為是否為「合理使用」,因此一旦引發爭議,就需要進入司法程序,由法院個案判斷。對AI開發者來說,降低法律風險的解法,一是和內容製作單位逐一洽談合作,授權費用相對算力、硬體花費不算貴,但這個方式取得資料雖然「乾淨」,量體卻往往不足以撐起AI模型訓練所需;因此有些台灣AI開發者選擇走在灰色地帶,採取「釋出模型、但不說明訓練使用的資料集」做法,著作權利人若要訴諸侵權,必須負擔舉證責任。
面對訓練生成式AI模型所衍生的著作權爭議,各國做法不一,美國多起訴訟案件正在進行中,而歐盟與日本透過法律有更明確的定義與規範,台灣若要修法該向誰學習?
法律專家認為,「資料探勘」可設為例外,但必須要求開發者透明化、揭露訓練資料來源,不過對於營利與否的限制與執行方式,仍然有許多細節需要討論。數位發展部部長林宜敬受訪時指出,目前要形成社會共識很難,因此未來5年內不會推相關修法,現階段將先著力於成立「台灣主權AI訓練語料庫」希望能打破僵局——首先從中央各部會開始邀集語料,再進一步邀請地方政府加入,也預計與民間團體展開合作,只是目前都是「無償取得」,並沒有規劃支付授權的經費。
「我們被科技平台掌控,但是又不能不跟他合作,」《報導者》所接觸的新聞媒體高層大多支持主權AI發展,但「內容有價」仍是難以棄守的原則;他們並不一昧高喊「內容有價」口號,也努力思考新的合作模式可能⋯⋯
每一個個人都是AI使用者的讀者,你怎麼看這場圍繞在著作權與AI開發之間的討論?
点击图片查看原图

