2
1
0

这个哥们牛逼plus啊。
把一个 WebAssembly(WASM)解释器 hard-coded的方式嵌入到了 Transformer 模型的权重里,而且是无损的(losslessly)。
这相当于在 LLM 内部运行着一台真正的计算机。
这台计算机可以 实际执行计算(run
IT技术
(
twitter.com
)
由
Rainier
提交
这个哥们牛逼plus啊。
把一个 WebAssembly(WASM)解释器 hard-coded的方式嵌入到了 Transformer 模型的权重里,而且是无损的(losslessly)。
这相当于在 LLM 内部运行着一台真正的计算机。
这台计算机可以 实际执行计算(run computations),而不是像现在大多数模型那样,只是通过infer来给出计算结果。
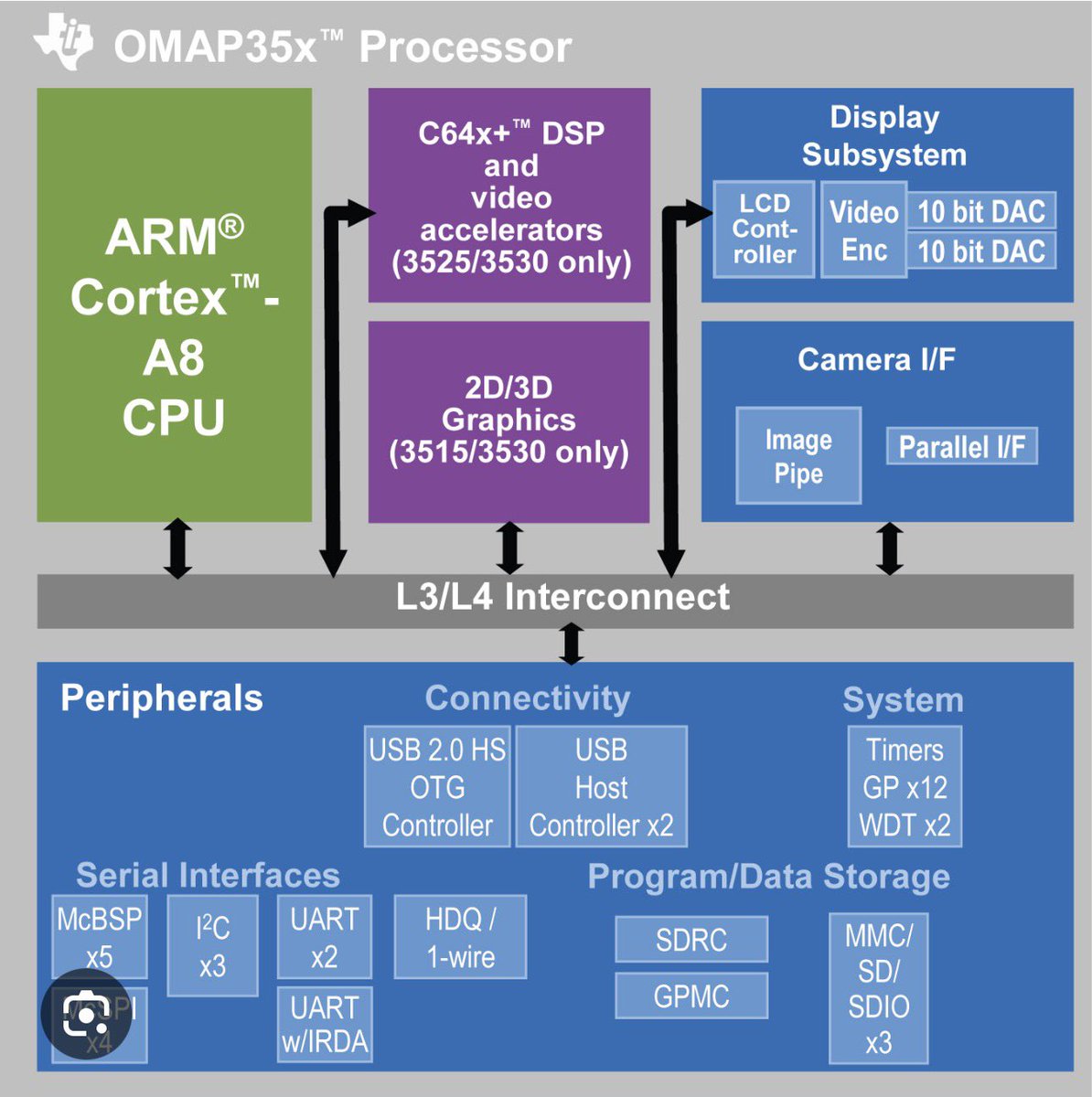
这个思路有点类似于TI的dsp芯片,
arm负责逻辑思维,然后dsp专门负责高速数据计算。各取所长。
那么类比一下,LLM 老算不清3.11 与3.8哪个大的问题可以通过构建一种 混合架构(hybrid architectures):
1. 神经网络 负责 推理和理解(reasoning)
2. 嵌入式解释器 / 计算引擎 负责 高精度计算
这样就能同时兼顾 智能推理能力 和 确定性计算精度。
这对,数值计算,物理模拟,金融建模,密码学运算有很大好处。
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
3
590
589
589
6
517
516
516
8
114
113
113
14
107
106
106
17
478
477
477
18
478
477
477
25
257
256
256

