2
1
0

不管是 OpenClaw 还是其他一些 AI 客户端,都喜欢用 markdown 文件来存储记忆
好处是简单、方便、易维护,就像 yetone 说他打开 alma 的记忆,发现 AI 悄悄塞了一句喜欢他 md 记忆用在大型工程其实缺点很多:
1. 每次需要使用记忆的时候,都需要全量 load 记忆 md,这非常消耗 token
2. 随着 md
时政
(
twitter.com
)
由
𝙋𝙖𝙨𝙨𝙡𝙪𝙤
提交
不管是 OpenClaw 还是其他一些 AI 客户端,都喜欢用 markdown 文件来存储记忆
好处是简单、方便、易维护,就像 yetone 说他打开 alma 的记忆,发现 AI 悄悄塞了一句喜欢他
md 记忆用在大型工程其实缺点很多:
1. 每次需要使用记忆的时候,都需要全量 load 记忆 md,这非常消耗 token
2. 随着 md 文件变长,放在文件中间的逻辑规则极易被 AI 忽略(是的,AI 也和人一样更关注文章的开头和结尾 😅)
3. md 的检索通常基于关键词或向量,但在大型项目中,我们需要的是内容的「关系」,单靠关键词的记忆非常容易关系链断裂
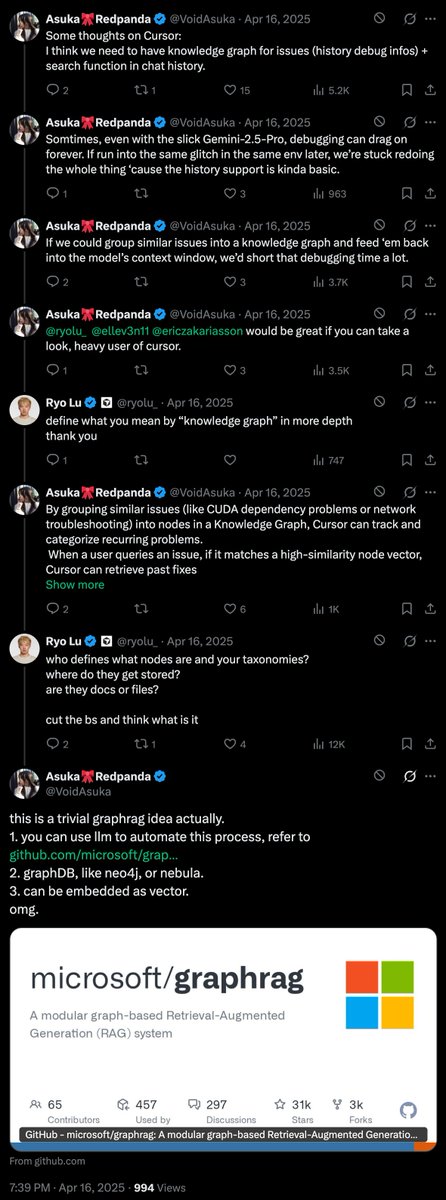
这让我想起来上次小能猫和 ryo 的对线,其实给 ai 客户端引入 Knowledge Graph 来存储记忆是非常有道理的
我翻了下,OpenClaw 官方是否定了引入 KG 改进记忆系统的方案的(参考项目 github 上的 issue #3730)
但我依然觉得,未来在 AI 记忆方面将会有很多工程化的创新,甚至可以诞生一些独角兽级别的创业公司,而且这是正儿八经的面向 AI Agent 的服务
比如现在那个 mem0(OpenMemory)感觉就很有希望,但依然还在早期
各位技术大佬们加油吧,这是未来 AI 创业的新思路和新范式
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
4
475
474
474
6
582
581
581
8
476
475
475
10
510
509
509
14
254
253
253
19
105
104
104

