
Seedance 2.0 这几天是真的火,X 上到处都是它生成的视频,又一次让海外 AI 圈羡慕国内 AI 圈。
影视飓风的 Tim 昨晚发了测试视频,对技术本身评价很高:分镜设计、运镜、音画匹配都是质的飞跃。
IT技术
(
twitter.com
)
Seedance 2.0 这几天是真的火,X 上到处都是它生成的视频,又一次让海外 AI 圈羡慕国内 AI 圈。
影视飓风的 Tim 昨晚发了测试视频,对技术本身评价很高:分镜设计、运镜、音画匹配都是质的飞跃。
那条视频我也看了,其中他提到一个问题:上传自己照片做参考图时,生成视频的声音和他本人很像,而他从未提供过任何声音样本。
这倒不奇怪,影视飓风在全网有大量高清视频,肯定已经被用作训练数据。
之前谷歌 Veo 3 推出时,人们发现生成的视频也很像一些知名创作者的作品;OpenAI 最早推出 Sora 时,外媒也测试到它能高度模仿经典电影片段。用公开数据训练是国内外大模型的共同做法,Tim 作为明星级公众人物,素材进入公开数据集并不意外。
这种担忧挺合理的,但这趋势我们挡不住,现在已经没有人能阻挡 AI 的加速了。
最早音色克隆技术出来的时候,大厂掌握了技术但不敢放开,反倒是小团队先做出来发布了,慢慢大家也就跟进接受了。
这几天大火的 ClawdBot/OpenClaw 也是同样的路径,各种隐私安全问题被讨论,但因为是个人小团队项目,大家宽容度明显更高,等大厂后续下场反而更容易被接受。
这种事大厂反而能让人放心一点,大厂有能力也有动力去做合规限制,小作坊下料才是真的猛。
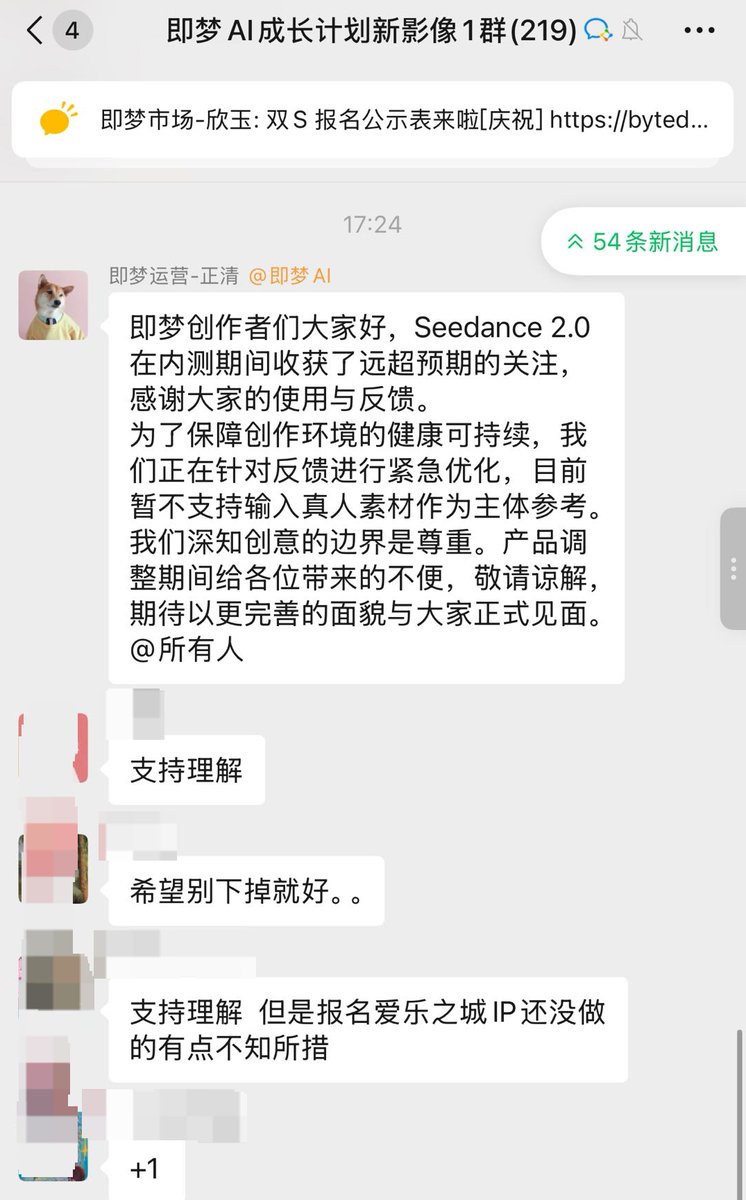
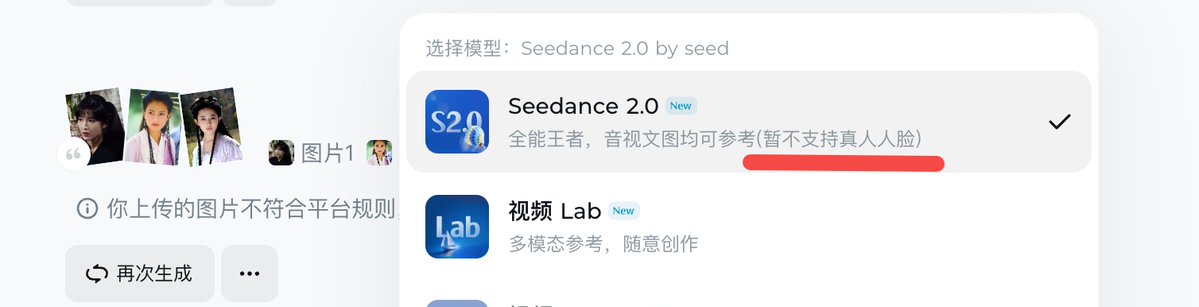
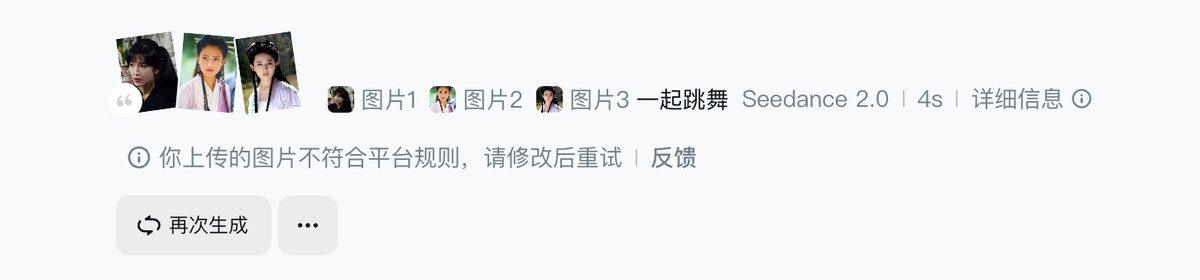
事实上即梦已经限制了真人人脸生成视频,大厂在技术狂奔时还是会守住一些底线。
结果倒是很多人在那哀叹,限制了真人人脸生成视频,少了一些可以测试的例子,很多视频都成了绝版。
与其焦虑不如多想想怎么在技术创新与数据合规之间找到平衡。
像 Sora 2 的分身(Chapter)功能就是一个不错的尝试方向,让你既能享受技术带来的乐趣,又减少一些隐私上的担忧。比如我给孩子制作了分身,我只会给家人分享,不会让别人用。
好消息是,人们对 AI 生成的音频视频正在建立起更多辨别力和免疫力,这本身也是一种自然的适应过程。我也经常跟家人朋友科普让他们小心 AI 视频。
我自己有个小技巧是先看视频时长是不是 10 秒 15 秒这种整数,不过这招已经快像看 AI 图片人物有没有六根手指一样不灵了。
你们都用什么技巧分辨 AI 生成的图片或者视频呢?
点击图片查看原图
点击图片查看原图
点击图片查看原图

