3
2
1

想从零理解神经网络的工作原理,光看 PyTorch 或 TensorFlow 的文档很难搞懂底层逻辑,那些封装好的 API 让人知其然不知其所以。
最近在 GitHub 上发现 tensor.h 这个教学项目,用纯 C 语言从零实现一个微型张量库,没有任何依赖,把神经网络训练的核心机制讲得明明白白。
时政
(
twitter.com
)
由
GitHubDaily
提交
想从零理解神经网络的工作原理,光看 PyTorch 或 TensorFlow 的文档很难搞懂底层逻辑,那些封装好的 API 让人知其然不知其所以。
最近在 GitHub 上发现 tensor.h 这个教学项目,用纯 C 语言从零实现一个微型张量库,没有任何依赖,把神经网络训练的核心机制讲得明明白白。
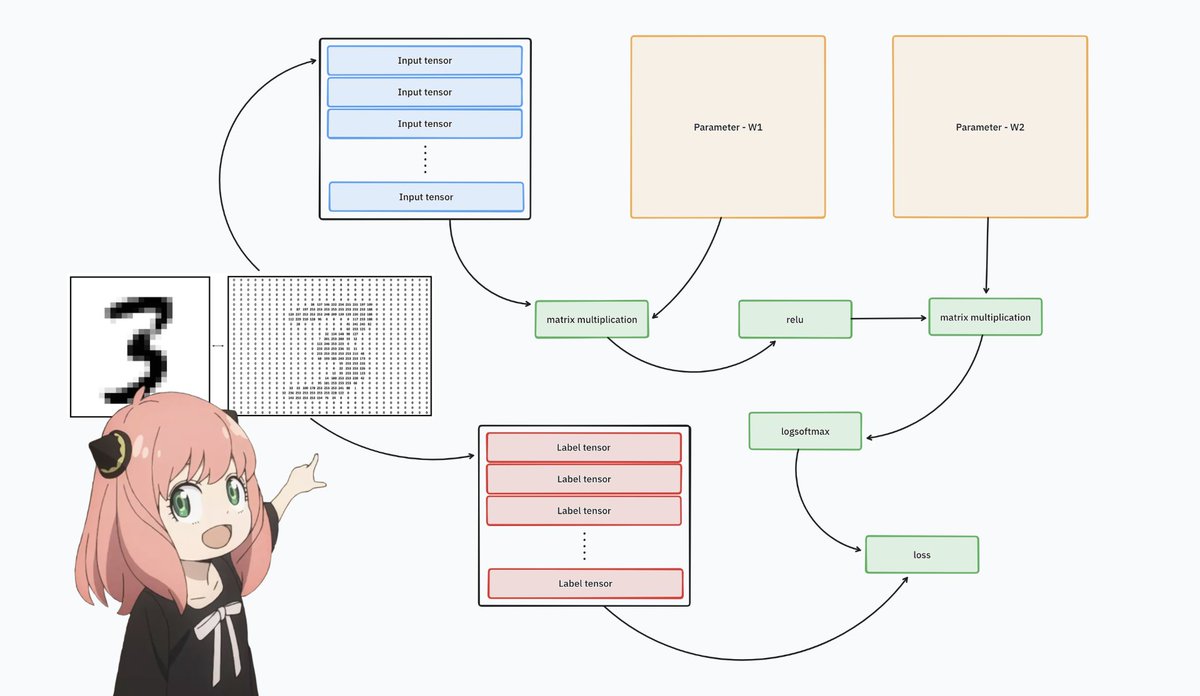
作者用"猫狗分类"这个经典例子切入,解释了神经网络本质上就是一种特殊函数,通过矩阵乘法、ReLU、LogSoftmax 等数学运算,配合可训练的参数(权重)来完成任务。
GitHub:https://t.co/k07MxxsoQa
整个教程涵盖张量的创建和操作、损失函数定义、自动求导(Autograd)机制、各类运算的前向和反向传播实现,最后用 MNIST 手写数字识别展示完整训练流程。
每个概念都配有详细代码和数学推导,从 N 维数组的 shape 和 strides 原理,到链式法则如何计算梯度,再到训练循环中的参数更新,循序渐进讲透每个环节。
如果你想把神经网络从"黑盒工具"理解到"可控机制",这份教程值得仔细读一遍。
点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
1
85
84
84
4
103
102
102
6
38
37
37
9
373
372
372
10
479
478
478
17
315
314
314
19
237
236
236
20
213
212
212
22
72
71
71
25
185
184
184

